


There’s a familiar, yet often overlooked, user interface (UI) concept re-emerging in the age of generative AI: the zoomable user interface—a boundless virtual space or infinite canvas where users can create, arrange, and interact with content beyond the constraints of a traditional screen or page. Before the generative AI (GenAI) craze, the infinite canvas was largely reserved for creative software like graphics-editing tools (Photoshop), UI design platforms (Figma), CAD applications (AutoCAD), and brainstorming apps. Most "business and productivity" software adhered to a standard of pages, frames, slides, or windows as constrained areas for work. Our interface norms are “document” centric, whether it’s for writing, spreadsheets, accounting, etc.
A growing number of startups are leveraging the infinite canvas for AI-based content generation and manipulation in a context that breaks away from traditional creative use.
Here are a few that have caught my attention:
Hyperspace Compute

Hyperspace Compute offers a clever user interface for AI agents focused on deep research and analysis, using a combination of web search, code execution, and several selectable models. It is part of the broader Hyperspace AI suite, which uniquely operates in a peer-to-peer model for running AI—an innovation in itself!
In this context, the canvas approach is useful for representing AI agents visually, where each node represents an editable step in a process. This visual representation breaks down the complexity of the service and provides clear visual controls, including each agent's prompt, task, and model. Imagine how overwhelming a simple chat thread would be for managing such a large number of prompts and customisations.
Hyperspace Play

On the other hand, Hyperspace Play provides a more straightforward solution. Think of Perplexity or ChatGPT with search capabilities—Play helps users explore topics based on web and custom sources, utilising both chat and canvas layouts. Here, representing each chat session as a node on the canvas allows for a visual overview that helps preserve context across different topics.
Kosmik 3
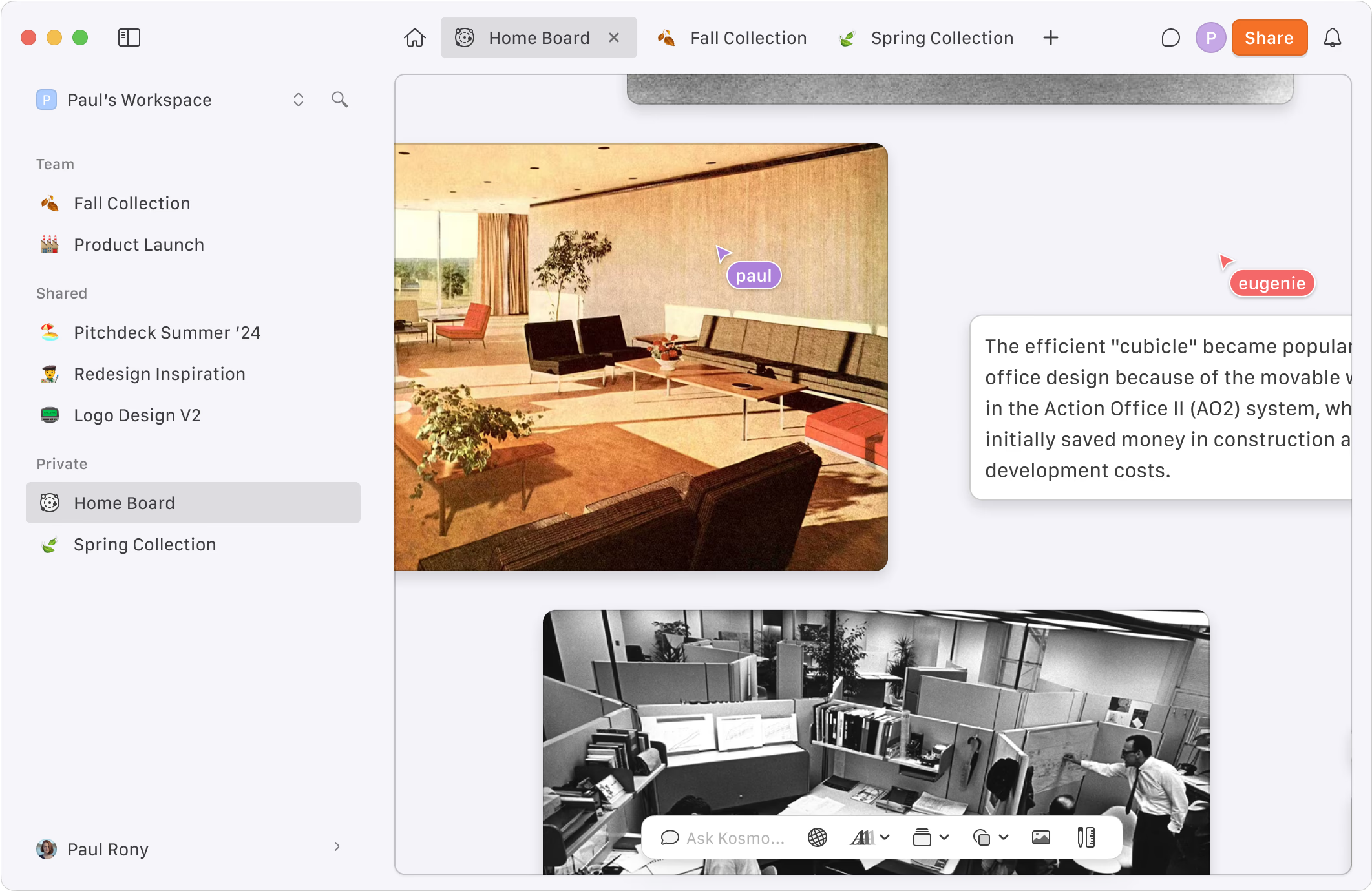
Another intriguing startup is Kosmik. I used an earlier version, but they have since rebuilt it, and Kosmik 3 is yet to be released. Kosmik reimagines the web browser with a more fundamental approach to the infinite canvas. Instead of traditional tabs, Kosmik employs a canvas where users can interact with various objects, such as a web page, document, or PDF, all within the canvas itself. It will also support GenAI features, allowing users to interact with content like images or documents through prompts, keeping everything within context.
The concept of a canvas is not an entirely new interface paradigm. It dates back to Ivan Sutherland's groundbreaking demo of Sketchpad in 1963. Since then, there have been numerous attempts to make the canvas a primary operating system interface, such as Pad++(1996). However, these Zoomable User Interfaces failed to capture the mainstream imagination. Instead, the amalgamation of WIMP-based (Windows, Icons, Menus, Pointers) concepts from Xerox PARC and the desktop metaphor popularised by Apple became the dominant paradigm. There’s an interesting discussion on StackExchange (2018) on why these interfaces didn’t really work.
Ted Nelson, a visionary in computing, critiqued traditional GUIs by coining the term "Parc User Interfaces" (PUIs or, as he playfully puts it, "Poois"). Nelson argued that these interfaces fundamentally mimic the limitations of paper-based systems, practically accommodating for print, restricting users from fully engaging with the dynamic possibilities of digital media. His critique goes beyond the interface itself, challenging the very design philosophy behind it.
Today, the comeback of the infinite canvas seems to be driven by:
The iterative nature of text and image generation, where users often need to rapidly create, inspect, modify, and connect content.
Ease of interaction with disposable GenAI outputs: For example, when generating multiple images, users can easily delete a canvas element (or an image) while preserving the context of other elements. Comparing that to iterating on 5-6 iterations of an image on MidJourney in a Discord chat shows the advantage.
A potential alternative to chat interfaces: Chat interfaces, popularised by ChatGPT, are nice but limited by extremely long threads that can lead to a loss of context and increased cognitive load. Infinite canvases provide a more organised structure for managing interactions visually.
One can imagine how such features are useful, even in productivity software, like writing, data analysis, workflow management, etc.
Another major area where the infinite canvas excels is in node-based programming environments like Unreal Engine's Blueprint system, and the more modern Unit which—despite their challenges, see picture below—demonstrate how an infinite canvas can intuitively represent interconnected, complex elements.
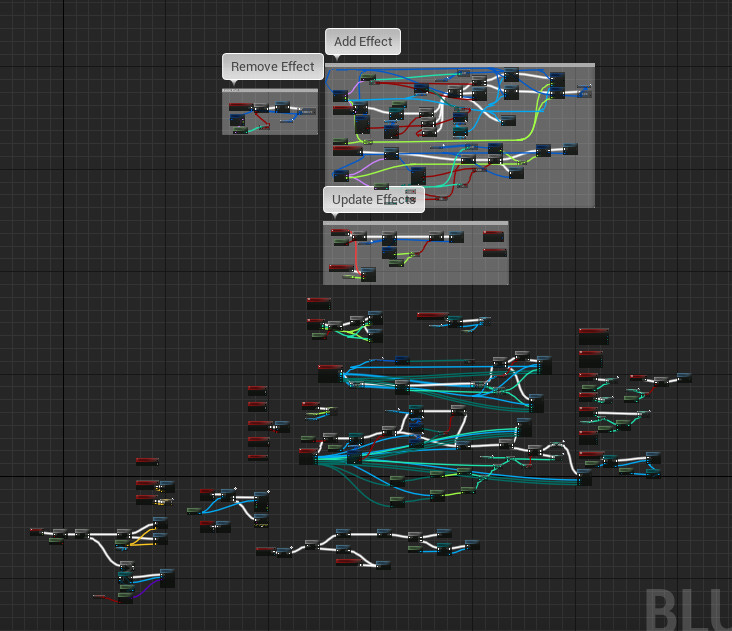
It seems to me that the limitations of our current interfaces—confined windows and the emulation of paper—are reaching their limits with GenAI. Canvases approach content in a non-linear block-by-block manner, rather than a sequential flow. This shift is facilitated by the convergence of powerful hardware, modern development frameworks, canvas frameworks like React Flow and Konva, and GenAI capabilities, unlocking new opportunities for startups to utilise the canvas metaphor.
There are more examples, such as Ideogram's Canvas for image generation and manipulation, getimage.ai, visuali.io, DeckFlow, dreamspace.art, HyperSpatial, recraft.io, FacetAI Generative Canvas, and every single traditional design software like Canva, Figma, Miro stuffed AI features into their infinite canvas and are pushing these AI + Canvas features on everyone.
Is that the future?
Whether this trend will succeed and be dominant on an OS level, I don't know. Keep in mind most of our modern computing is done on mobile and a canvas isn’t particularly helpful there, yet. Perhaps its’s the wrong question—there is no one-size-fits-all solution in computing, and the push for “the future of” is more of a businessy take. If the question is whether the canvas will replace the established WIMP + Desktop approach, I am doubtful. Not because they’re better, but because users have learned and adapted to the traditional GUIs on Mac and Windows for almost 40 years now; such entrenched habits are not easily unlearned. The traditional GUI has clear advantages, and we're likely to see iterations that blend the best of both worlds.
The infinite canvas does solve some problems, but it brings its own —chief among them is context loss and cognitive overload, again! Imagine being stuck in a sprawling web of interconnected nodes, unsure where it starts or ends, especially after hours or weeks of exploration. The lack of boundaries, typically provided by pages or windows, can sometimes be more of a bug than a feature. That’s why constraining the canvas is sometimes useful, as seen in automation tools like Make, where structured workflows are more effective. Moreover, transporting media (such as printing these documents for whatever reason) is challenging with a canvas, since it's inherently tied to a big screen. What will probably work is a more fundamental reimagining of the canvas itself, which is worthy of a company on its own and it’s not easy!
The current GenAI + Canvas trend is still in its infancy. We will continue to see iterations on its use, along with attempts to redefine established norms.
Whether ‘redefining interactions’ is essential for every AI startup is debatable. However, GenAI has undoubtedly sparked new possibilities in computing, inviting exploration.